2023. 2. 6. 15:44ㆍReact JS
참고:
sheetJS의 xlsx.mjs 소스코드와
https://www.youtube.com/watch?v=NAfhj49daQg
html에는 표로 된 table 태그가 있습니다.
그리고 살다보면 html table에 있는 데이터를 엑셀로 다운 받아 확인하거나, 보고용으로 사용해야할 때도 있습니다.
저는 테이블과 json데이터를 엑셀파일로 추출하기 위하여 XLSX 모듈을 사용하였습니다.
xlsx는 sheet js의 모듈인데요, 이 링크는 sheetjs 공식문서 입니다.
간편하게 보실분은 밑의 블로그로 들어가시면 됩니다.
https://wickedmagica.tistory.com/248
[Node.js] Excel 파일 생성하고 데이터 읽기
API : https://www.npmjs.com/package/xlsx ■ 엑셀 데이터 읽어오기 $ npm install xlsx ■ 엑셀 데이터 읽어오기 # 엑셀파일 # 소스코드 excel_file_read.js// @breif xlsx 모듈추출const xlsx = require( "xlsx" ); // @files 엑셀 파
wickedmagica.tistory.com
그럼 본격적으로 시작해보겠습니다
예를 들어 이런 화면이 있습니다. 그리고 저 파란색 "엑셀 다운로드" 버튼을 클릭한다면 그 다음 이미지처럼 스타일이 먹여져 엑셀이 다운로드 되어집니다.
이것에 대해서 포스팅을 해보고자 합니다.

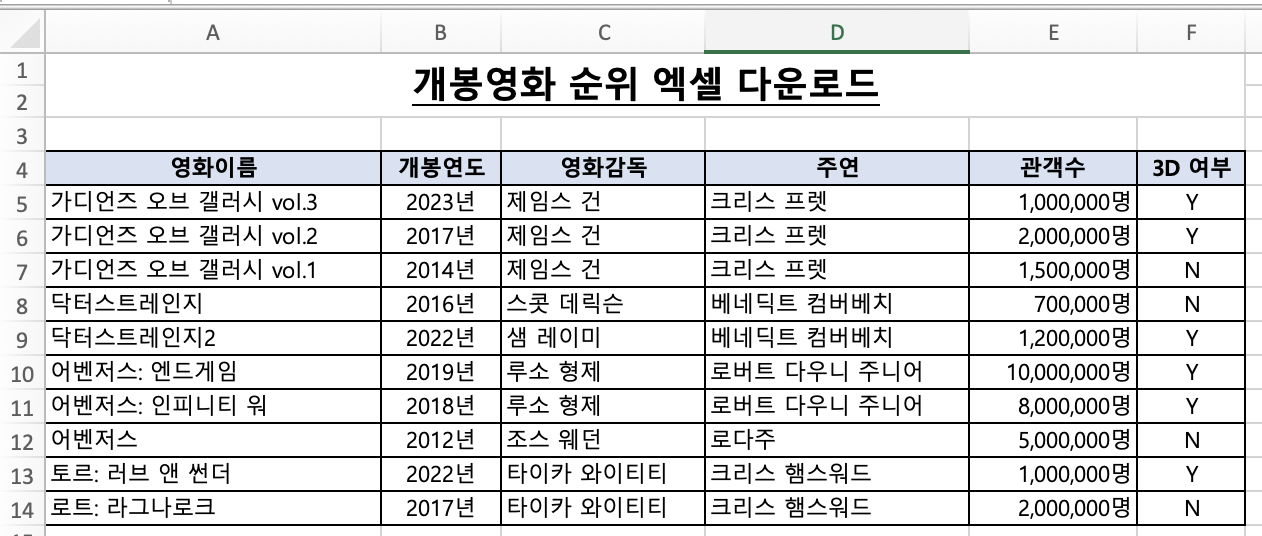
먼저,
위 화면에서 테이블은 데이터를 어떻게 출력할까요?
데이터는 아래에 콘솔을 찍어보았듯이 key: value 로 이루어신 object의 배열로 이루어져 있습니다.
바로 JSON 형식으로 데이터가 존재하는 것이죠.

그리고 테이블 컴포넌트에서 thead의 각 컬럼의 th에 표시될 텍스트와(labelName) 위에서 보여드린 데이터에서 매핑할 key이름(name) 그리고 데이터의 포맷 등이 담긴 rowDef를 데이터가 담긴 list와 함께 <TableLayout />에 prop으로 넘겨주었습니다.
const rowDef = [
{
type: no,
labelName: 'No.'
},
{
labelName: '영화이름',
name: 'movieNm'
},
{
labelName: '개봉연도',
name: 'releasedYear',
format: numberFormatWithSuffixYear
},
{
labelName: '영화감독',
name: 'directorNm'
},
{
labelName: '주연',
name: 'actor'
},
{
labelName: '관객수',
name: 'attendence',
format: numberFormatWithSuffixPeople
},
{
labelName: '3D 여부',
name: '3DYn'
}
];
return <TableLayout layoutHeaderName={layoutHeaderName} rowDef={rowDef} list={list} buttonsDef={buttonsDef} />;
주목해야할 것은 table의 각 컬럼이 json 데이터의 key를 매핑한다는 것입니다.
이 점을 이용하여 Json 데이터를 xlsx 모듈을 이용하여 엑셀 시트로 출력할 수 있는 것이죠.
서버에 요청을 보내고 이를 받는 것을 가장한 fetch 함수와 이 함수의 isExcel 인자를 true로 주는 "엑셀 다운로드" 버튼을 <TableLayout />에 넘겨주는 buttonsDef입니다.
만약 isExcel값을 주지 않거나 false로 준다면 서버에서 응답 받은 데이터로 html의 table 데이터를 지정해주는 것이며 true로 준다면 이 데이터로 엑셀을 작성하여 다운로드 하게 하는 것입니다.
const fetch = (isExcel) => {
const res = movieList;
const _list = res.map((e) => {
return {
movieNm: e.movieNm,
releasedYear: e.releasedYear,
directorNm: e.directorNm,
actor: e.actor,
attendence: e.attendence,
'3DYn': e['3DYn'],
text: e.text
};
});
if (isExcel) json2XLSX(rowDef, _list, `${layoutHeaderName} 엑셀 다운로드`);
else setList(_list);
};
const buttonsDef = [
{
labelName: '엑셀 다운로드',
onClick: () => {
fetch(true);
}
}
];그럼 이제 isExcel이 true일 때 호출하는 함수인 if (isExcel) json2XLSX(rowDef, _list, `${layoutHeaderName} 엑셀 다운로드`);에 대해서 이야기를 하고자 합니다.
sheetj-style, xlsx-populate 모듈을 사용했기 때문에 두 모듈을 설치해주세요.
npm i sheetj-style
// 혹은
yarn add sheetjs-stylenpm i xlsx-populate
// 혹은
yarn add xlsx-populate
ExcelUtil.js에 이런 함수를 만들어 두었습니다.
json데이터를 xlsx 형태로 변환해주는 함수인데요, 인자로는 헤더 및 컬럼의 정보가 담긴 rowDef, 그리고 데이터들이 담겨 있는 list, 파일 이름과 엑셀시트에 제목이 될 layoutHeaderName 그리고 엑셀시트의 제목을 적을지 안 적을지 결정하는 noTitleHeader 가 있습니다.
1번부터 4번까지는 데이터를 정제하고 5번에 엑셀시트에 데이터를 작성하고 6번부터 8번까지는 엑셀시트 스타일링을 위한 작업을 한 뒤 9번에서 엑셀시트에 스타일을 더해 다운로드합니다.
/**
* 서버에 전체 데이터를 요청하여 그 응답을 해당 테이블 형식에 맞게 해서 엑셀 파일로 추출하는 메서드
* @param rowDef 컬럼의 속성 정보가 담긴 rowDef
* @param list 데이터가 담긴 리스트
* @param layoutHeaderName 파일명 => TableLayout의 layoutHeaderName 프롭에 주시는 값을 주시면 됩니다.
* @param noTitleHeader 엑셀시트의 1,2 번 로우에 제목이 적히는 지 않적히는 지 여부
*
* {1} : 만약 헤더가 두 줄로 되어 있는 경우 두개의 row로 만들기 위한 함수
* {2} : rowdef의 순서에 맞게 json데이터의 값들도 정렬
* => 전체가 배열, 한 row 그 전체 배열의 배열, 내부 배열의 값들은 엑셀 셀에 들어갈 데이터들
* {3} : 엑셀파일의 헤더가 될 라벨네임과 colspan, rowspan을 추출
* {4} : 헤더가 맨 윗 줄이 되고, 그 밑에 헤더 name에 의해서 정렬된({2} 참고) 배열도 추가
* {5} : 준비된 데이터를 이제 엑셀파일 워크북으로 변환
* {6} : 데이터의 길이가 동일한 컬럼의 인덱스들, 데이터가 1,000% 같이 숫자인 컬럼의 인덱스들을 구합니다.
* {7} : 헤더 부분만 특별히 스타일링 해주기 위해서 헤더의 row 길이를 여기서 구했습니다.
* {8} : 스타일링을 위해서 sheetObj의 headerRowLen에 {6}번 값 삽입
* {9} : 엑셀시트 오브젝트를 스타일 먹이고 파일로 다운로드 하기
*/
const json2XLSX = (rowDef, list, layoutHeaderName, noTitleHeader) => {
/* {1} */
const headerVal = seperateRowDef(rowDef);
console.log(`headerVal => ${JSON.stringify(headerVal)}`);
/* {2} */
const tdDataValues = extractOnlyValues(list, rowDef);
console.log(`tdDataValues => ${JSON.stringify(tdDataValues)}`);
/* {3} */
const headerLabels = extractLabelNameFromHeaderVal(headerVal);
console.log(`headerLabels => ${JSON.stringify(headerLabels)}`);
/* {4} */
const wholeData = headerLabels.concat(tdDataValues);
console.log(`wholeData => ${JSON.stringify(wholeData)}`);
/* {5} */
const sheetObj = json_to_book(layoutHeaderName, wholeData, noTitleHeader);
/* {6} */
const { equalLengthColumnIndexList, numberFormatIndexList } = getColumnWidthInfo(tdDataValues);
/* {7} */
const headerRowLen = headerVal.length;
/* {8} */
sheetObj['headerRowLen'] = headerRowLen;
sheetObj['equalLengthColumnIndexList'] = equalLengthColumnIndexList;
sheetObj['numberFormatIndexList'] = numberFormatIndexList;
/* {9} */
executeHandleExport(sheetObj, PageOrWhole.whole, layoutHeaderName, noTitleHeader);
};아래는 위의 코드블럭에서 사용하는 함수들입니다.
/**
* 헤더가 두 줄 이상이 될 수도 있다는 점을 고려하여 두 줄 이상일 시 한개의 배열을 여러개로 찢는 메서드
* @param rowDef 헤더 정보
* @returns 두 줄 이상일 시 한개의 배열을 여러개로 찢는 메서드
*/
const seperateRowDef = (rowDef) => {
const headerVals = [];
let currentArray = rowDef;
while (currentArray.length > 0) {
// 맨위의 레벨 headerVals에 다 집어 넣기 => 그 다음에 업데이트 된 다음 세대 애들을 headerVals에 다 집어 넣기
headerVals.push(currentArray.map((item) => item ?? ''));
// nextLevelArray에 이것의 자식들을 다 집어넣어 currentArray를 업데이트 시킴
const nextLevelArray = [];
currentArray.forEach((item) => {
if (item.children) {
nextLevelArray.push(...item.children);
}
});
// 없다면 안 집어넣음
currentArray = nextLevelArray;
}
return headerVals;
};
/**
* 화면에 보여진 값들만 추출된 객체를 headerName의 순서에 맞게 정렬시킨 후 값들만 배열로 반환한다.
* @param list 헤더에 등록된 것만 구별된 json 데이터
* @param rowDef 헤더 정보
* @returns 순서에 맞게 정렬된 값들만 추출 후 배열로 반환
*/
const extractOnlyValues = (list, rowDef) => {
const fittedData = arrangeValues(list, rowDef);
const tdDataValues = extractValuesToArray(fittedData);
return tdDataValues;
};
/**
* object 내에서 rowDef와는 상관 없이 뒤죽박죽이 되어있을 key: value 들을 rowDef에 정의된 순서대로 정렬하고 포맷 등 rowDef의 다양한 옵션대로 value작성한다.
* @param list 헤더에 등록된 것만 구별된 json 데이터
* @param rowDef 헤더 정보
* @returns
*
* 결과적으로
* [{undefined: 1, menuGrpNm: '해피페이머니', menuId: 'Money', menuNm: '해피페이머니', menuUrl: '/', …},
* {undefined: 2, menuGrpNm: '해피페이머니', menuId: 'MemberInfoMgmt', menuNm: '회원정보관리', menuUrl: '/memberInfoMgmt', …}]
* 이런 형태로 정렬됨
*/
const arrangeValues = (list, rowDef) => {
let i = 1;
const fittedData = list.map((row) => {
const { newRow, newI } = getNewRowsAndNewI(rowDef, row, i);
i = newI;
return newRow;
});
return fittedData;
};
/**
* rowDef에는 type: no일 시 rownum을 작성하는 것, value의 포매팅(format, dynamicFormat) 혹은
* 다른 어떤 값에 따라 value가 어떻게 되는 것(valueCondition)등에 대한 옵션이 있는데 이 옵션들을 적용하여 엑셀시트에 작성될 데이터들을 작성한다.
* @param {Array} rowDef 헤더 정보
* @param {object} row 여러줄의 데이터(list) 중 하나의 row 즉 하나의 Json string
* @param {number} i rows의 인덱스 번호
* @returns
*/
const getNewRowsAndNewI = (rowDef, row, i) => {
const newRow = {};
rowDef.forEach((header) => {
const headerNm = header.name;
if (headerNm !== undefined) {
// if (header.format) newRow[headerNm] = header.format(row[headerNm] ?? '');
// else if (header.valueCondition) newRow[headerNm] = header.valueCondition(row);
// else newRow[headerNm] = row[headerNm];
let targetValue;
if (header.valueCondition) targetValue = header.valueCondition(row);
else targetValue = row[headerNm] ?? '';
if (header.format) targetValue = header.format(targetValue ?? '');
else if (header.dynamicFormat) targetValue = header.dynamicFormat(targetValue ?? '');
newRow[headerNm] = targetValue;
} else if (header.type == no) {
// 헤더의 타입이 No.라면 직접 번호 값을 주는 것으로
const isNoHide = header.noHideCondition ? header.noHideCondition(row) : false;
if (isNoHide) {
newRow[headerNm] = '';
} else newRow[headerNm] = i++;
}
if (header.children) {
// const rowOfChild = getNewRowsAndNewI(header.children, row, i);
const { newRow: rowOfChild } = getNewRowsAndNewI(header.children, row, i);
Object.assign(newRow, rowOfChild);
}
});
return { newRow: newRow, newI: i };
};
/**
* 순서에 맞게 정렬 및 작성된 객체에서 그 값들만 추출 후 배열로 반환
* @param fittedData 순서에 맞게 정렬된 객체 배열
* @returns 순서에 맞게 정렬된 객체에서 그 값들만 추출 된 배열
*/
const extractValuesToArray = (fittedData) => {
const tdDataValues = fittedData.map((item) => {
return Object.entries(item).map((val) => {
return val[1] ?? '';
});
});
return tdDataValues;
};
/**
* 엑셀파일의 헤더가 될 라벨네임과 colspan, rowspan을 추출
* @param headerVal
* @returns 라벨네임과 colspan, rowspan을 추출된 객체 배열
*/
const extractLabelNameFromHeaderVal = (headerVal) => {
const headerLabels = headerVal.map((item) => {
const eachLabelArr = item.map((innerItem) => {
const labelName = innerItem.labelName;
if (innerItem.rowSpan || innerItem.colSpan) {
let cellInfo = {};
if (innerItem.rowSpan && innerItem.rowSpan > 1) {
cellInfo['rowspan'] = innerItem.rowSpan;
}
if (innerItem.colSpan && innerItem.colSpan > 1) {
cellInfo['colspan'] = innerItem.colSpan;
}
cellInfo['value'] = labelName;
return cellInfo;
}
return labelName;
});
return eachLabelArr;
});
return headerLabels;
};
/**
* 엑셀시트에 스타일을 적용할 시 숫자 포맷인 컬럼, 문자열인데 모든 데이터의 길이가 동일한 컬럼은 스타일링을 별도로 해주기 위해 해당 컬럼들의 인덱스를 저장 반환한다.
* @param {바디 정보} tdDataValues
* @returns {equalLengthColumnIndexList, numberFormatIndexList} 데이터의 길이가 동일한 컬럼의 인덱스들, 데이터가 1,000% 같이 숫자인 컬럼의 인덱스들
*/
const getColumnWidthInfo = (tdDataValues) => {
const arrLength = tdDataValues[0].length;
let isDatasLengthOfEachColumnNotEqualList = new Array(arrLength);
let columnDataLengthList = new Array(arrLength);
let isNotNumberFormatList = new Array(arrLength);
tdDataValues.forEach((row, rowIdx) => {
row.forEach((item, idx) => {
const itemLength = item.length;
if (!['합계', '소계'].includes(item) && itemLength > 0) {
if (!isDatasLengthOfEachColumnNotEqualList[idx]) {
if (columnDataLengthList[idx] && columnDataLengthList[idx] !== itemLength && rowIdx > 0) {
isDatasLengthOfEachColumnNotEqualList[idx] = true;
} else {
isDatasLengthOfEachColumnNotEqualList[idx] = false;
}
columnDataLengthList[idx] = itemLength;
}
if (!isNotNumberFormatList[idx] && rowIdx > 0) {
const regex1 = /^(\D)*-?(\d{1,3},)*(\d{1,3})(\.\d*[1-9]+)?$/g; // 단위가 앞에 있는 경우
const regex2 = /^-?(\d{1,3},)*(\d{1,3})(\.\d*[1-9]+)?(\D)*$/g; // 단위가 뒤에 있는 경우
if (regex1.test(item) || regex2.test(item)) {
isNotNumberFormatList[idx] = false;
} else {
isNotNumberFormatList[idx] = true;
}
}
}
});
});
const equalLengthColumnIndexList = isDatasLengthOfEachColumnNotEqualList.map((e, idx) => (e === false && e !== undefined ? idx : undefined)).filter((e) => e !== undefined);
const numberFormatIndexList = isNotNumberFormatList.map((e, idx) => (e === false && e !== undefined ? idx : undefined)).filter((e) => e !== undefined);
return { equalLengthColumnIndexList, numberFormatIndexList };
};
/**
* 엑셀시트 오브젝트를 스타일 먹이고 파일로 다운로드 하는 메서드
* @param sheetObj
* @param pageOrWhole 현재 페이지인지 아니면 전체 데이터인지
* @param layoutHeaderName 파일 제목
*/
const executeHandleExport = (sheetObj, pageOrWhole, layoutHeaderName, noTitleHeader) => {
const fileNm = setFileNameByItsPurpose(pageOrWhole, layoutHeaderName);
const { ws: workBook } = sheetObj;
delete sheetObj.ws;
handleExport(workBook, sheetObj, noTitleHeader).then((url) => {
const downloadAnchorNode = document.createElement('a');
downloadAnchorNode.setAttribute('href', url);
downloadAnchorNode.setAttribute('download', `${fileNm}.xlsx`);
downloadAnchorNode.click();
downloadAnchorNode.remove();
});
};
/**
* 현재 페이지인지 아니면 전체 데이터인지 구분하여 _전체 라는 것을 추가해준다.
* @param pageOrWhole 현재 페이지인지 아니면 전체 데이터인지
* @param layoutHeaderName 파일 제목
* @returns 파일 이름 + 년도날짜시간 합하여 파일명을 반환
*/
const setFileNameByItsPurpose = (pageOrWhole, layoutHeaderName) => {
const today = getFormatDate(new Date());
switch (pageOrWhole) {
case PageOrWhole.page:
return `${layoutHeaderName}_${today}.xlsx`;
case PageOrWhole.whole:
return `${layoutHeaderName}.xlsx`;
// case PageOrWhole.whole:
// return `${layoutHeaderName}_전체_${today}.xlsx`;
default:
return;
}
};
/**
* 지금 날짜, 시간 을 계산하여 반환하는 메서드
* @param date new Date()
* @returns 20230309+시간
*/
const getFormatDate = (date) => {
var year = date.getFullYear(); //yyyy
var month = 1 + date.getMonth(); //M
month = month >= 10 ? month : '0' + month; //month 두자리로 저장
var day = date.getDate(); //d
day = day >= 10 ? day : '0' + day; //day 두자리로 저장
var hour = date.getHours(); //hh
hour = hour >= 10 ? hour : '0' + hour; //hh 두자리로 저장
var minites = date.getMinutes(); //mm
minites = minites >= 10 ? minites : '0' + minites; //minute 두자리로 저장
var seconds = date.getSeconds(); //ss
seconds = seconds >= 10 ? seconds : '0' + seconds; //second 두자리로 저장
return year + month + day + hour + minites + seconds; //'-' 추가하여 yyyy-mm-dd 형태 생성 가능
};그 결과 [{},{}]의 형태였던 rowDef로 headerVal은 [[{},{}],[{},{}]]이 되었습니다. 배열 안의 하나의 배열은 한 row, 그리고 그 안의 object들은 각 컬럼의 정보입니다.

만약 table에서 컬럼이 두 줄이라면 어떻게 될까요?
그럴 시 rowDef에 colSpan, rowSpan, childrens옵션을 추가하면 됩니다.
const rowDef = [
{
type: no,
rowSpan: 2, // 추가
labelName: 'No.'
},
{
labelName: '영화이름',
rowSpan: 2, // 추가
name: 'movieNm'
},
{
labelName: '개봉연도',
name: 'releasedYear',
rowSpan: 2, // 추가
format: numberFormatWithSuffixYear
},
{
labelName: '출연진',
colSpan: 2, // 추가
children: [ // 추가
{
labelName: '영화감독',
name: 'directorNm'
},
{
labelName: '주연',
name: 'actor'
}
]
},
{
labelName: '관객수',
name: 'attendence',
rowSpan: 2, // 추가
format: numberFormatWithSuffixPeople
},
{
labelName: '3D 여부',
rowSpan: 2, // 추가
name: '3DYn'
}
];
이 경우 headerVal을 콘솔로 찍어본다면 아래와 같이 나옵니다. 다시 말해 배열 안의 하나의 배열은 한 row, 그리고 그 안의 object들은 각 컬럼의 정보인 것이지요.

tdDataValues는 list와 rowDef를 이용하여 본문의 값들만 순서를 정렬한 배열들의 배열입니다. 배열 안의 한 배열은 한 row인 것이죠.

headerLabels는 위의 headerVal에서 엑셀시트의 헤더 부분을 작성하는 데 필요한 데이터만 순서에 맞게 추출 및 정리한 것입니다.
colspan과 rowspan은 셀을 병합하는 데 있어서 세로 혹은 가로로 몇개의 셀을 병합할지에 대한 정보이며 value는 셀에 입력할 데이터입니다.
만일 자료형이 object가 아닌 그저 string이라면 그것은 그냥 value 인 것입니다.

그리고 wholeData는 headerLabels와 tdDataValues를 합친 것입니다. 이제 이 wholeData를 이용하여 엑셀시트에 데이터를 작성할 것입니다.

그냥 sheets-js의 XLSX모듈을 사용하면 제일 좋겠지만 rowDef안에 있는 colSpan, rowSpan등을 이용한 셀 병합등의 작업을 XLSX의 순수 기능만으로 구현하는데에는 한계가 있다고 느꼈습니다.
그래서 브라우저에서 f12를 누르면 개발자/관리자 모드를 들어갈 수 있잖아요? 거기서 제가 사용하고 있는 자바스크립트 라이브러리의 소스파일을 볼 수가 있는데 거기서 필요한 코드를 가져와 저의 목적에 맞게 커스터마이징을 하였습니다.
아래 코드는 CustomizedXlsx.js에서 파일 이름(title), 셀에 작성할 헤더와 본문의 정보가 담긴 배열(wholeData), 엑셀시트에 크게 타이틀을 작성할지 말지를 알려주는 noTitleHeader를 인자로 받아 엑셀시트 정보가 담긴 object를 반환하는 함수입니다.
/*! xlsx.js (C) 2013-present SheetJS -- http://sheetjs.com */
/* vim: set ts=2: */
/*exported XLSX */
/* SheetJS 라이브러리의 소스코드를 수정 보완한 것입니다. */
/**
* 테이블의 전체 데이터(JSON형식)를 (전체 페이지) 엑셀파일 워크북 객체로 반환하는 메서드
* @param title layoutHeaderName
* @param wholeData
* @param opts 맨위의 설명과 같습니다.
* @param noTitleHeader 시트 내에 맨 위의 헤더타이틀이 안뜨게 하고 싶으실 경우 true
* @returns
*/
function json_to_book(title /*:?string*/, wholeData /*:HTMLElement*/, noTitleHeader /*:? boolean */, opts /*:?any*/) /*:Workbook*/ {
//eslint-disable-line no-unused-vars
let sheetObj = parse_json(title, wholeData, noTitleHeader, opts);
return returnWorkbook(sheetObj, opts);
}
function parse_json(title /*:?string*/, wholeData /*:HeaderArray*/, noTitleHeader /*:? boolean */, _opts /*:?any*/) /*:Worksheet*/ {
// opts: sheet 정보.
var opts = _opts || {};
// dense가 없으니 object에. 이거는 sheet의 워크싯이된다.
var ws /*:Worksheet*/ = opts.dense ? ([] /*:any*/) : ({} /*:any*/);
return sheet_add_json(title, ws, wholeData, noTitleHeader, _opts);
}
/**
* 워크싯 데이터를 워크북으로 반환하는 메서드
* @param {*} sheetObj
* @param {*} opts 맨위의 설명과 같습니다.
* @returns 워크북 객체
*/
function returnWorkbook(sheetObj, opts) {
sheetObj['ws'] = sheet_to_workbook(sheetObj.ws, opts);
return sheetObj;
}
/**
* 엑셀 시트 이름과 엑셀시트에 들어갈 데이터를 집어넣는 메서드
* @param sheet sheetObj
* @param opts 맨위의 설명과 같습니다.
* @returns 엑셀 시트 이름과 엑셀시트에 들어갈 데이터
*/
function sheet_to_workbook(sheet /*:Worksheet*/, opts) /*:Workbook*/ {
var n = opts && opts.sheet ? opts.sheet : 'Sheet1';
var sheets = {};
sheets[n] = sheet;
return { SheetNames: [n], Sheets: sheets };
}
/**
*
* @param title layoutHeaderName
* @param ws 이제 워크싯 정보를 담을 빈 객체
* @param {*} wholeData
* @param noTitleHeader 시트 내에 맨 위의 헤더타이틀이 안뜨게 하고 싶으실 경우 true
* @param _opts 맨위의 opt 설명과 같습니다.
* @returns {ws: 데이터가 로우, 컬럼에 맞게 저장된 워크싯, colLen: 최대 컬럼 길이, totalRowLen: 헤더 포함 총 로우 길이} html 돔 데이터를 엑셀시트에 옮겨 적은 객체
*
* {1} : or_R은 엑셀 시트에서 데이터 시작 로우 인덱스이며 or_C는 데이터 시작 컬럼 인덱스입니다.
* 1-2번 로우는 제목이 들어가므로 4번째 줄(3번 인덱스)부터 데이터를 시작하도록 하였습니다.
* {2} : 헤더와 바디를 합친 배열입니다.
* {3} : Math.min() 함수는 주어진 숫자들 중 가장 작은 값을 반환합니다. 여기서 sheetRows는 그냥 rows.length 가 됩니다.
* {4} : 밑으로 가시면서 많이 보시게 될 구조 입니다. range는 모든 데이터를 담았을 때의 전체 범위 입니다. 최대 로우, 최대 컬럼이 담길 것입니다.
* => { s(start): { r(row index): 0, c(col index): 0 }, e(end): { r(row index): or_R, c(col index): or_C } };
* {5} : merges는 데이터들의 rowspan, colspan 정보를 담는 객체배열입니다.
* {6} : 이또한 밑으로 가시면서 많이 보시게 될 구조 입니다.
* => { t(type)): 's(string)', v(value): title }
* titleO는 자료형은 string, 값을 title이라는 객체입니다.
* {7} : encode_cell은 데이터를 엑셀시트에 적는 행위라고 보시면 됩니다.
* => ws[XLSX.utils.encode_cell({ c: 0, r: 0 })] = titleO; 특정 좌표에 자료형과 값으로 이루어진 객체를({5} 참고) 집어넣었습니다.
* 즉, 0번 컬럼, 0번 로우에 제목을 적겠다는 의미입니다.
* {8} : 모든 tr들을 돌면서 그 안의 정보들을 활용합니다.
* {8-1} : 한 row 즉, wholeData[idx]
* {8-2} : 한 row의 값들을 돌변서 labelName 및 속성들을 활용합니다.
* {8-2-1} : elements 즉 한 row의 각 data들
* {8-2-2} : v => 값 사용자에 보이는 한 td의 text value 혹은 labelName
* {8-2-3} : 이전에 merge라는 개체에 들어 간 colspan이나 rowspan이 있다면 그것을 계산 하여 그 다음 셀에 데이터를 넣어주는 곳입니다.
* {8-3} : colSpan 속성을 가져옵니다. 없다면 그냥 1
* {8-4} : rowspan 속성을 가져옵니다. 없다면 그냥 1
* {8-5} : 숫자면 숫자, 날짜면 날짜 포매팅 해주는 곳 => rowDef의 format 함수 사용하여 포매팅 처리하였습니다.
* {8-6} : merge 되었을 때 merge 된 컬럼인덱스까지로 한 셀을 병합시켜줍니다.
* {8-7} : 현재 셀의 colspan을 반영하여 다음 컬럼으로 이동합니다.
* {9} : merge 된 것이 있다면 워크시트에서 병합하는것을 담당하는 ws['!merges']에 그 동안 축적했던 merges 데이터를 합칩니다.
* {10} : unshift() 메서드는 새로운 요소를 배열의 맨 앞쪽에 추가하고, 새로운 길이를 반환합니다.
* 이 부분은 이미 셀 병합한 것이 있을 경우 제목의 범위를 위에 2줄 + 최대 컬럼 수 까지 키워주는 곳입니다.
* 헤더타이틀을 안 넣을 옵션을 줄 시는 실행하지 않습니다.
* {11} : 이 부분은 이미 셀 병합한 것이 없을 경우 제목의 범위를 위에 2줄 + 최대 컬럼 수 까지 키워주는 곳입니다.
* {12} : ws['!ref']는 엑셀 시트에 데이터를 쓸 범위를 의미합니다.
* {13} : 전체 데이터를 집어 넣는 곳 마지막에 한번만 합니다.
* {14} : 헤더 로우 수에 대한 정보는 wholeData에 헤더와 바디의 구분이 없으니 이 함수를 호출한 곳에서 계산해줍니다.
*
* {15} : 헤더 로우 수에 대한 정보는 wholeData에 헤더와 바디의 구분이 없으니 이 함수를 호출한 곳에서 계산해줍니다.
* {15-1} : 각 컬럼의 width를 담는 배열
* {15-2} : 문자열의 바이트 사이즈를 구하고 이에 2를 더한다. 2를 더하는 이유는 컬럼의 너비에 조금 여유를 주기 위함이다.
* {15-2-1} : 내용이 긴 열은 40,50,50에서 너비 조정
* {15-3} : 문자열 길이의 최대값을 지정함.
*/
function sheet_add_json(title /*:?string*/, ws /*:Worksheet*/, wholeData /*: wholeData*/, noTitleHeader /*:? boolean */, _opts /*:?any*/) /*:Worksheet*/ {
//eslint-disable-line no-unused-vars
var opts = _opts || {};
if (DENSE != null) opts.dense = DENSE;
/* {1} */
var or_R = noTitleHeader ? 0 : 3,
or_C = 0;
// opts는 그저 빈 객체이므로 PASS
if (opts.origin != null) {
if (typeof opts.origin == 'number') or_R = opts.origin;
else {
var _origin /*:CellAddress*/ = typeof opts.origin == 'string' ? XLSX.utils.decode_cell(opts.origin) : opts.origin;
console.log(`_origin => ${_origin}`);
or_R = _origin.r;
or_C = _origin.c;
}
}
/* {2} */
var rows /*:wholeData*/ = wholeData; // sheet_add_dom과 다른 부분
// console.log("rows => ", rows) // 주석을 해제해보세요.
/**
* ex)
* [[{"rowpan":2,"value":"No."},{"colSpan":2,"value":"A"},{"colSpan":2,"value":"B"}],
* ["카드번호","상품명","유효기간","카드발급신청일자"]]
*/
/* {3} */
var sheetRows = Math.min(opts.sheetRows || 10000000, rows.length);
/* {4} */
var range /*:Range*/ = { s: { r: 0, c: 0 }, e: { r: or_R, c: or_C } };
// ws는 현재 그저 빈 객체이므로 PASS
if (ws['!ref']) {
var _range /*:Range*/ = XLSX.utils.decode_range(ws['!ref']);
range.s.r = Math.min(range.s.r, _range.s.r);
range.s.c = Math.min(range.s.c, _range.s.c);
range.e.r = Math.max(range.e.r, _range.e.r);
range.e.c = Math.max(range.e.c, _range.e.c);
if (or_R == -1) range.e.r = or_R = _range.e.r + 1;
}
/* {5} */
var merges /*:Array<Range>*/ = [],
midx = 0;
var _R = 0,
R = 0,
_C = 0,
C = 0,
RS = 0,
CS = 0;
/* {6} */
var titleO /*:Cell*/ = { t: 's', v: title };
/* {15} */
let colLengthArr;
if (opts.dense) {
if (!ws[0]) ws[0] = [];
ws[0][0] = titleO;
} else if (!noTitleHeader) {
/* {7} */
ws[XLSX.utils.encode_cell({ c: 0, r: 0 })] = titleO;
}
if (!ws['!cols']) ws['!cols'] = [];
/* {15-1} */
colLengthArr = new Array(rows[rows.length - 1].length);
/* {8} */
for (; _R < rows.length && R < sheetRows; ++_R) {
/* {8-1} */
var row /*:WholeData*/ = rows[_R];
// 여기서는 wholeData의 각 element들 value가 있으면 하고 없으면 넘어가고 해야겠다.
/* {8-2} */
for (_C = C = 0; _C < row.length; ++_C) {
/* {8-2-1} */
var elt = row[_C];
// console.log(`elt => ${JSON.stringify(elt)}`);
/* {8-2-2} */
var v /*:?string*/ = elt.value ? elt.value : elt; // sheet_add_dom과 다른 부분
// console.log(`v(textContent) => ${v}`);
// z는 뭘해도 null 이 나오는 애입니다.
var z /*:?string*/ = null; // sheet_add_dom과 다른 부분
/* {8-2-3} */
for (midx = 0; midx < merges.length; ++midx) {
var m /*:Range*/ = merges[midx];
// console.log(`m => ${JSON.stringify(m)}`);
if (m.s.c == C + or_C && m.s.r < R + or_R && R + or_R <= m.e.r) {
C = m.e.c + 1 - or_C;
midx = -1;
}
// console.log(`2 => ${JSON.stringify(m)}`);
}
/* TODO: figure out how to extract nonstandard mso- style */
/* {8-3} */
CS = elt.colspan ?? 1; // sheet_add_dom과 다른 부분
// console.log(`CS => ${CS}`);
/* {8-4} */
if ((RS = +elt.rowspan || 1) > 1 || CS > 1) merges.push({ s: { r: R + or_R, c: C + or_C }, e: { r: R + or_R + (RS || 1) - 1, c: C + or_C + (CS || 1) - 1 } }); // sheet_add_dom과 다른 부분
// console.log(`RS => ${RS}`);
/* {15-2} */
let columnWidth = byteSize(v, true) + 2;
/* {15-2-1} */
if (columnWidth >= 42 && columnWidth < 52) columnWidth = 42;
else if (columnWidth >= 52 && columnWidth < 62) columnWidth = 52;
else if (columnWidth > 62) columnWidth = 62;
/* {15-3} */
if (colLengthArr[C] < columnWidth || colLengthArr[C] === undefined) {
colLengthArr[C] = columnWidth;
}
// {6} 참고
var o /*:Cell*/ = { t: 's', v: v };
// _t, 얘도 뭘해도 그냥 빈칸이 나옵니다.
var _t /*:string*/ = ''; // sheet_add_dom과 다른 부분
/* {8-5} */
if (v != null) {
if (v.length == 0) o.t = _t || 'z';
else if (v === 'TRUE') o = { t: 'b', v: true };
else if (v === 'FALSE') o = { t: 'b', v: false };
}
// console.log(`o => ${JSON.stringify(o)}`);
if (o.z === undefined && z != null) o.z = z;
/* The first link is used. Links are assumed to be fully specified.
* TODO: The right way to process relative links is to make a new <a> */
// opts는 그저 빈 객체이므로 PASS
if (opts.dense) {
if (!ws[R + or_R]) ws[R + or_R] = [];
ws[R + or_R][C + or_C] = o;
} else ws[XLSX.utils.encode_cell({ c: C + or_C, r: R + or_R })] = o;
/* {8-6} */
if (range.e.c < C + or_C) range.e.c = C + or_C;
/* {8-7} */
C += CS;
}
++R;
}
// console.log(`merges => ${JSON.stringify(merges)}`);
/* {9} */
if (merges.length) ws['!merges'] = (ws['!merges'] || []).concat(merges);
range.e.r = Math.max(range.e.r, R - 1 + or_R);
/* {10} */
if (!noTitleHeader) {
if (ws['!merges']) ws['!merges'].unshift({ s: { r: 0, c: 0 }, e: { r: 1, c: range.e.c } });
/* {11} */ else ws['!merges'] = (ws['!merges'] || []).concat({ s: { r: 0, c: 0 }, e: { r: 1, c: range.e.c } });
}
// console.log(`range => ${JSON.stringify(range)}`);
/* {12} */
ws['!ref'] = XLSX.utils.encode_range(range);
/* {13} */
if (R >= sheetRows) ws['!fullref'] = XLSX.utils.encode_range(((range.e.r = rows.length - _R + R - 1 + or_R), range)); // We can count the real number of rows to parse but we don't to improve the performance
/* {14} */
const res = {
// sheet_add_dom과 다른 부분
// worksheet
ws: ws,
// 한 줄 최대 컬럼 길이
colLen: range.e.c,
// 헤더 줄 수는 바깥에서.
// 헤더 포함 모든 로우 수
totalRowLen: sheetRows,
// 각 컬럼의 너비를 담은 배열
colLengthArr: colLengthArr
};
return res;
}반환된 값을 찍어보니 스타일링을 위한 정보들과 엑셀 워크 시트 정보가 담긴 ws도 있습니다. 이제 여기까지 데이터가 정제 되었습니다.
마지막 단계에서는 엑셀 시트를 스타일링하고, 이를 다운로드를 받을 것입니다.

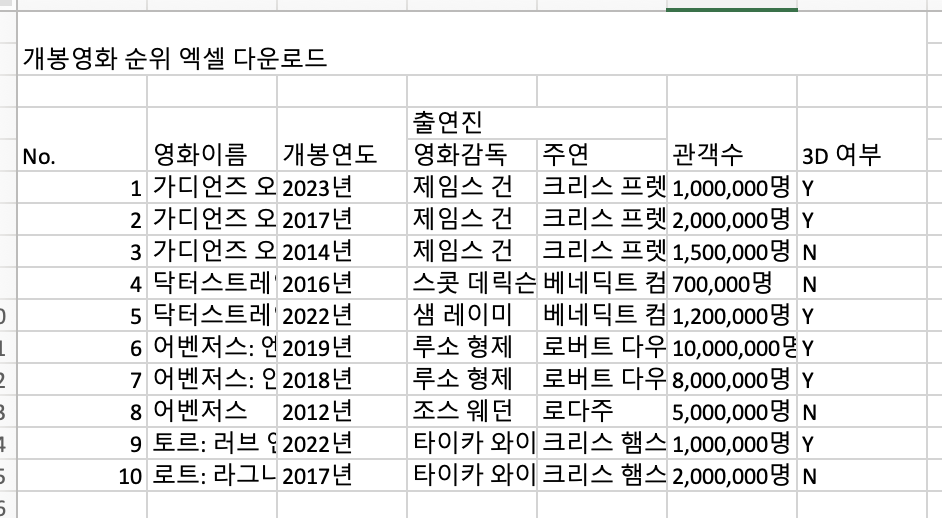
오늘 포스팅은 여기까지구요, 엑셀 시트를 스타일링하고, 이를 다운로드를 받는 것은 다음 포스팅에서 이어 하도록 하겠습니다.
감사합니다.
깃허브 소스코드 : https://github.com/kingkiboots/ReactXlsxDownloadWithCustomizedXLSXAndXlsxPopulate.git
'React JS' 카테고리의 다른 글
| [React JS] webpack으로 build 시 html에 환경변수 넣는 법 (1) | 2024.01.26 |
|---|---|
| [React JS] Spring Boot 내에서 React 어플리케이션 구동시키기 (2) | 2024.01.25 |
| [React JS]Jquery fadeIn/Out javascript로 변경하기 (0) | 2023.12.18 |
| [React JS] 무한히 늘어나는 숫자를 ###,###,### 형식으로 포매팅하기 (0) | 2023.06.23 |
| [React JS] 1,000,000 형식의 가격에서 ,를 지웠을 때 그 앞 숫자도 지워지게 하는 법 (0) | 2023.03.30 |